Как уже было сказано, дискретная форма представления информации является наиболее общей и универсальной. В виде совокупности символов, принадлежащих к ограниченному алфавиту, можно представить как текст или массивы чисел, так и оцифрованные звук и изображение. С учетом этого очевидно, что должны существовать универсальные методы сжатия данных (цифровой информации), применимые ко всем ее разновидностям. В силу своей универсальности эти методы должны исключать потерю информации (такая потеря может быть допустима при передаче, например мелкой детали изображения, но неприемлема, когда речь идет, скажем, о коде программы). С другой стороны, в ряде приложений общие методы наверняка не будут наиболее эффективными. Например, в силу особенностей зрительного и слухового восприятия, некоторое «огрубление» изображения или звука может оказаться малозаметным, при этом выигрыш в объеме передаваемых данных окажется значительным. В этих случаях уместно использовать специальные методы сжатия с потерями (рис.5.1).
При кодировании со сжатием без потерь выделяются две разновидности методов: Первая основана на раздельном кодировании символов. Основная идея состоит в том, что символы разных типов встречаются неодинаково части и если кодировать их неравномерно, – так, чтобы короткие битовые последовательности соответствовали часто встречающимся символам, – то в среднем объем, кода будет меньше. Такой подход, именуемый, статистическим кодированием, реализован, в частности, в широко распространенном коде Хаффмана, о котором мы расскажем подробно ниже.
Очевидно, что посимвольное кодирование не использует такого важного резерва сжатия данных, как учет повторяемости последовательностей (цепочек) символов.
Простейший вариант учета цепочек – так называемое «кодирование повторов» или код RLE, когда последовательность одинаковых символов заменяется парой – “код символа + количество его повторов в цепочке”. В большинстве случаев цепочки одинаковых символов встречаются нечасто. Однако, например, при кодировании черно-белых растровых изображений, каждая строка которых состоит из последовательных черных или белых точек, такой подход оказывается весьма эффективным (он широко применяется при факсимильной передаче документов). Кроме того, кодирование повторов нередко используется как составной элемент более сложных алгоритмов сжатия.
Гораздо более универсальным является алгоритм, позволяющий эффективно кодировать повторяющиеся цепочки разных символов, имеющие при этом произвольную длину. Такой алгоритм был разработан Лемпелем и Зивом и применяется в разных версиях в большинстве современных программ-архиваторов. Идея алгоритма состоит в том, что цепочка символов, уже встречавшаяся в передаваемом сообщении, кодируется ссылкой на боле раннюю (при этом указываются «адрес» начала такой цепочки в «словаре» сообщения и ее длина). Ниже мы обсудим особенности алгоритма Лемпеля-Зива.
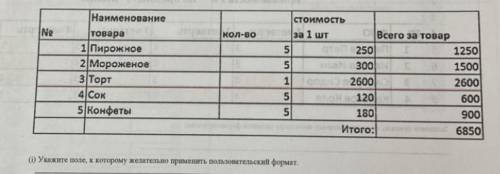
Объяснение:
Последовательность действий:
Перевези козу (так как с тигром оставлять нельзя он ее съест, а козу с морковкой нельзя она ее съест)
Переправься обратно один.
Перевези тигра (на том берегу останется пока одна морковка)
Перевези козу (он ее забрал на тот остров, чтобы тигр не съел)
Перевези морковку (козу оставляет, потому что там тигр, да еще и морковка)
Переправься обратно один.
Перевези козу (он ее забирает)
Смысл задачи был, перевезти всех на противоположный берег, при условии что:
В лодке могут быть двое
Тигра с козой оставлять нельзя
Козу морковкой оставлять нельзя
Обзор подходов к сжатию информации
Как уже было сказано, дискретная форма представления информации является наиболее общей и универсальной. В виде совокупности символов, принадлежащих к ограниченному алфавиту, можно представить как текст или массивы чисел, так и оцифрованные звук и изображение. С учетом этого очевидно, что должны существовать универсальные методы сжатия данных (цифровой информации), применимые ко всем ее разновидностям. В силу своей универсальности эти методы должны исключать потерю информации (такая потеря может быть допустима при передаче, например мелкой детали изображения, но неприемлема, когда речь идет, скажем, о коде программы). С другой стороны, в ряде приложений общие методы наверняка не будут наиболее эффективными. Например, в силу особенностей зрительного и слухового восприятия, некоторое «огрубление» изображения или звука может оказаться малозаметным, при этом выигрыш в объеме передаваемых данных окажется значительным. В этих случаях уместно использовать специальные методы сжатия с потерями (рис.5.1).
При кодировании со сжатием без потерь выделяются две разновидности методов: Первая основана на раздельном кодировании символов. Основная идея состоит в том, что символы разных типов встречаются неодинаково части и если кодировать их неравномерно, – так, чтобы короткие битовые последовательности соответствовали часто встречающимся символам, – то в среднем объем, кода будет меньше. Такой подход, именуемый, статистическим кодированием, реализован, в частности, в широко распространенном коде Хаффмана, о котором мы расскажем подробно ниже.
Очевидно, что посимвольное кодирование не использует такого важного резерва сжатия данных, как учет повторяемости последовательностей (цепочек) символов.
Простейший вариант учета цепочек – так называемое «кодирование повторов» или код RLE, когда последовательность одинаковых символов заменяется парой – “код символа + количество его повторов в цепочке”. В большинстве случаев цепочки одинаковых символов встречаются нечасто. Однако, например, при кодировании черно-белых растровых изображений, каждая строка которых состоит из последовательных черных или белых точек, такой подход оказывается весьма эффективным (он широко применяется при факсимильной передаче документов). Кроме того, кодирование повторов нередко используется как составной элемент более сложных алгоритмов сжатия.
Гораздо более универсальным является алгоритм, позволяющий эффективно кодировать повторяющиеся цепочки разных символов, имеющие при этом произвольную длину. Такой алгоритм был разработан Лемпелем и Зивом и применяется в разных версиях в большинстве современных программ-архиваторов. Идея алгоритма состоит в том, что цепочка символов, уже встречавшаяся в передаваемом сообщении, кодируется ссылкой на боле раннюю (при этом указываются «адрес» начала такой цепочки в «словаре» сообщения и ее длина). Ниже мы обсудим особенности алгоритма Лемпеля-Зива.